
 As more and more customers are moving their mission-critical Oracle database workloads to virtualized infrastructure, I often get asked how to deal with Oracle’s requirement to reproduce issues on a physical environment (especially if they use VMware as virtualization platform – as mentioned in Oracle Support Note # 249212.1).
As more and more customers are moving their mission-critical Oracle database workloads to virtualized infrastructure, I often get asked how to deal with Oracle’s requirement to reproduce issues on a physical environment (especially if they use VMware as virtualization platform – as mentioned in Oracle Support Note # 249212.1).
In some cases, database engineers are still reluctant to move to VMware for that specific reason. But the discussion is not new – I remember a few years ago I was speaking in Vienna to a group of customers and partners from Eastern Europe, and these were the days we still had VMware ESX 3.5 as state-of-the-art virtualization platform. Performance was a bit limited (4 virtual CPUs max, some I/O overhead and memory limitations) but for smaller workloads it was stable enough for mission critical databases. So I discussed the “reproduce on physical in case of problems” issue and I stated that I never heared of any customer who really had to do this because of some issues. Immediately someone in the audience raised his hand and said, “well, I had to do that once!” – Duh, so far for my story…
Let’s say that very often I learn as much from my audience as (hopefully) the other way around 
Later I heard of a few more occasions where customers actually were asked by Oracle support to “reproduce on physical” because of suspected problems with the VMware hypervisor. In all of the cases I am aware of, the root cause turned out to be elsewhere (Operating System or configuration) but having to create a copy in case of issues is a scary thought for many database administrators – as it could take a long time and if you have strict SLAs then this might bite back at you.
So what is my take on this?
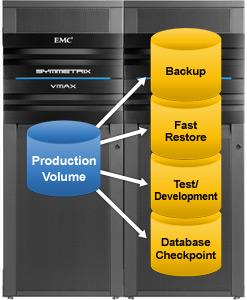
For starters, if you have the right tools and configuration, creating a fresh ad-hoc copy (clone) of a mission-critical production database is a fairly trivial thing to do. Even large databases can be cloned, in a consistent manner, within minutes using EMC cloning and snapshot technology (and many storage vendors have similar features – we could argue which implementation is better but that’s off-topic – let’s assume for now that with any decent enterprise storage platform you can do this
VMware itself also has snapshot features – however, that is currently limited to virtual machines only. So for this specific case it’s not going to help us out. That’s why I recommend my customers to put production databases on VMware RDM (Raw Device Mapping) devices. This allows interaction with EMC cloning tools (i.e. EMC Replication Manager, EMC Networker and the like).
For smaller environments you might not want to go through defining many RDM devices (LUNs) and prefer standard VMware VMFS/VMDK volumes. I expect that in the future we will have good enough integration between EMC and VMware that we can somehow clone VMDK volumes to physical environments – but that’s up to the engineering people of the respective companies (I just can mention it over and over again and put some pressure on new developments – and it helps if our customers do the same!)
But small VMDK files (say, any database smaller than 500GB or so) can be quickly copied by other means (worst case, perform a full restore from a fast disk-based backup system such as EMC Data Domain).
“But I need a separate server standing by all the time to put my cloned database on!” is another common objection (or cry for help, if you will). Yes – that is true. Even with the awesome EMC cloning methods you need something to mount your copy onto – and it cannot be another virtual machine – hence it must be a separate, spare physical server of roughly the same architecture, and running the same OS and configuration (and be connected to the same SAN, obviously).
Now if you limit your view of the world to just one database, then having a spare server for the unlikely case of mounting a cloned database onto when you have to, doesn’t sound very attractive. But my customers are not building virtualized datacenters just to run one database or application. And if you’re going to run hundreds of virtual machines with databases, applications, infrastructure components, etc. then the overhead of having one spare server is not too much. Even better – if you use a blade server platform that has stateless computing nodes (such as Cisco UCS, the system that is used in VCE VBlock) then applying a specific “template” to make this spare blade work immediately as a database server for mounting a production copy for the moment, is pretty easy to do. And having one or more spare blades to compensate for either hardware failures, or spikes in compute power requirements, is a good idea anyway.
So let’s conclude that fulfilling Oracle’s requirement to “reproduce on physical” is quick and trivial to do (once you set up the right infrastructure). Would there be any benefits in this approach instead of just extra trouble?
Let’s compare two scenarios. One where we don’t have any cloning features for mission-critical databases and one where we do (regardless whether we run virtual or physical).
Scenario one: no cloning facilities.
The phone rings at the help desk and angry users complain something is wrong with their application. Although the application is not down, there still are some issues that need to be fixed. The issues seem to be database related. You call your application or database vendor for support. They request access to the production database in order to fix the issue (either through some kind of remote access or the support person is physically in your office to get access).
Now the 3rd party support engineer has no clue about your change management procedures (such as ITIL). He has one goal: resolve the problem as quickly as possible, then hit and run away as fast as possible (more issues to solve elsewhere). So how is this person going to behave?

He (or she) logs in on the database with DBA access and looks around. He might think he needs a specific database patch and is going to apply it. Didn’t work. Try another one. Didn’t work. Hmm, let’s drop an index and add another one. Let’s reorganize that table. Let’s change that configuration setting. Modify some special user rights. You get the picture – by the time the problem is fixed, the support person performed a bunch of changes to the production environment that are not audited, not tracked in the change management system and most likely no-one else knows about it. The support guy is gone and the problem is fixed, but the changes might cause new issues (either directly or much later). You end up with an uncontrolled environment on which changes happen that you are unaware of.
Not to mention that support people can make severe mistakes as well (drop an entire table, for example, or worse). This all happens directly on the mission-critical production system!
Scenario two: sophisticated (EMC) cloning tools available
The phone rings at the help desk and angry users complain something is wrong with their application. Although the application is not down, there still are some issues that need to be fixed. The issues seem to be database related. You call your application or database vendor for support. They request access to the production database in order to fix the issue (either through some kind of remote access or the support person is physically in your office to get access).
 But you don’t want to take the risk of having 3rd party people messing around with production data. So you fire up the replication management tooling (i.e. EMC Replication Manager), quickly create a cloning job for the production database, assign the cloned copy to a spare (physical or virtual) server, and you fire the cloning job. Five minutes later the clone database is running – an exact, firefighting copy of production! You provide access to the support engineer.
But you don’t want to take the risk of having 3rd party people messing around with production data. So you fire up the replication management tooling (i.e. EMC Replication Manager), quickly create a cloning job for the production database, assign the cloned copy to a spare (physical or virtual) server, and you fire the cloning job. Five minutes later the clone database is running – an exact, firefighting copy of production! You provide access to the support engineer.
He logs in on the database with DBA access and – like in the first scenario – is going to resolve as quickly as possible. So he is going to try all kinds of things (reorg tables, drop and add indexes, apply patches, modify config settings, and more). You don’t care what he’s doing… Even if he would by accident drop complete tables or even the whole database, you just run the clone job again and 5 minutes later he has a fresh copy to mess around with. Once the problem is fixed (on the copy) you ask him what the fix was, you apply the fix, and that fix only, to production and you move on.
The benefits?
- A controlled, better audited production environment
- No remote access for unknown people to your mission critical systems (security, compliance!)
- No risk of accidental data loss during troubleshooting
- Compliance with Oracle’s requirement to reproduce on physical machine if needed
- The support person does not have to be too worried about breaking things so he might try a few more brutal things to fix the issue. If it doesn’t work – refresh copy and try something else
- You might want to keep the “broken” copy database around for a few hours or days to see if you can salvage some data or do some more analysis on the root cause – again without putting production data at risk
- Allows testing of troubleshooting skills in a risk-free environment
- Cloning tools have many other interesting purposes, as I explained before
So my take on the matter? Whether or not Oracle is asking for it, I would ALWAYS make a “firefighting” copy (physical or virtual, whatever works best) before doing serious troubleshooting…
1818 total views , 1 views today
Comments are closed.