

As an advocate on database virtualization, I often challenge customers to consider if they are using their resources in an optimal way.
And so I usually claim, often in front of a skeptical audience, that physically deployed servers hardly ever reach an average utilization of more than 20 per cent (thereby wasting over 80% of the expensive database licenses, maintenance and options).
Magic is really only the utilization of the entire spectrum of the senses. Humans have cut themselves off from their senses. Now they see only a tiny portion of the visible spectrum, hear only the loudest of sounds, their sense of smell is shockingly poor and they can only distinguish the sweetest and sourest of tastes.
– Michael Scott, The Alchemyst
About one in three times, someone in the audience objects and says that they achieve much better utilization than my stake-in-the-ground 20 percent number, and so use it as a reason (valid or not) for not having to virtualize their databases, for example, with VMware.
The first time this happened was a few years ago. I was thrown off guard and it took me a moment of thinking to figure out if it could be possible what this person claimed. I knew if I could not put this claim in perspective, the rest of my story would no be longer trustworthy.
My way of thinking was as follows: When engineers have to size production servers, they have no good way to figure out how much processing power they need. Typically the input they have to work with is something like:
“It’s application X using Oracle database, we expect to start with Y terabytes in size and Z concurrent users. We’re using application modules ABC and DEF and we have some custom reports and functions on top of the standard application. But our company is really unique so we cannot really compare our expected workload against anyone else that uses the same application stack. Please tell us what servers we need and what storage infrastructure is required in terms of performance and capacity. Oh and by the way we don’t know the future growth but we expect it to be between 30 and 60 per cent per year. Last but not least: we need application performance guarantees (SLAs) that may not be violated, ever.”
Sounds familiar?
So the engineer starts sizing and uses some Zen meditation, Voodoo economics, Black Magic and Witchcraft to figure out what he needs. Which typically ends up in thinking something like:
“I’ve seen similar applications in the past and for that they needed 200 bogotpms™. But here we have twice the number of users and double database size so I guess we need at least 600. And there is some uncertainty in how this custom app module works and how the business processes and users actually behave, so let’s double the number just in case (1200), and add 20% feelgoodtpms® (1440). But we also have to take future growth of 60 per cent into account for the next 3 years so that brings us close to 6000. Heck, I’m not paying for this server myself anyway and if I under-size I will get blamed, so let’s go for it”.
And so the server with 6000 bogotpms gets ordered – probably ending up doing an average of 350 bogotpms (a meaningless term I invented just for the sake of this discussion), bringing the server utilization to about 5%.
Now the storage sizing.
“Of course storage is considered to be extremely expensive (compared to application licenses) so we should hassle our storage vendor for 5% extra discount per gigabyte, but apart from that, let’s order a storage infrastructure with plenty of capacity, because next to my Y terabytes for the database itself, I need tier-1 storage for backup-to-disk (RMAN anyone?), archive logs, database exports and so on. But Flash capacity is the most expensive so let’s not buy too much of that. Our storage vendor tells us that modern enterprise storage offers much more performance than we will ever need, and we don’t have to worry about data layout or best practices – so let’s size for capacity and don’t worry too much about HoaxIOPS© and bandwidth.”
And so a storage environment gets ordered with lots of fast spinning rust (of course you need at least 15k rpm drives), and a small bit of Flash.
“And just because we can, we let our storage administrator configure everything in one large storage pool, and we will just configure volumes for our database out of that pool, based on the required capacity. Of course we put everything in RAID-1 because our database vendor tells us so (SAME). The storage vendor tells us they have “intelligent, dynamic, virtual storage tiering” so we can just dump all our database and non-database files on similar volumes from the pool. No need to worry about redo log behavior versus data files, indexes and whatever have you. Great innovation!”
Now given such scenarios, how is it possible that people in my audience sometimes claim much higher utilization than the 20% maximum that I’m talking about?
- They might have high I/O wait that drives up CPU utilization (without increasing performance obviously)
- Occasionally they run application processing and middle-ware on the same server (this does not result in higher database performance either but probably doubles reported CPU usage)
- They sometimes also run monitoring agents, host-based replication (i.e. ASM mirroring, Data Guard), ETL jobs etc on the same machine, again adding expensive CPU cycles without boosting transactional performance
- They frequently ignore many best practices such as enabling Linux huge pages, correctly setting disk alignment, and so on
- They only consider the highest loaded production server (this is where their focus goes all the time) and ignore the rest of the entire server landscape
- They don’t measure consistently and automated and across a long period but take a peek at the system every now and then using “top” or “sar” or similar (most likely during working hours…). Or don’t even bother to look at all except when… dealing with performance issues 😉
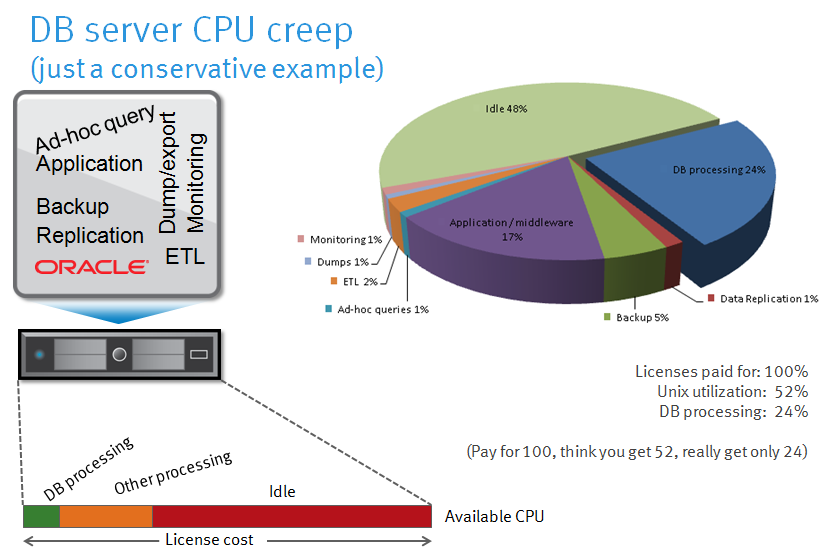
Furthermore, granted, some credit to some of them who actually do have pretty good utilization on their production server. If they run a 24×7 (web enabled) business then this is reasonable even without virtualization. But a business doesn’t just spend “Dirty Cache” [sic] on production systems. They also have a D/R system, a test & dev, acceptance, training environments, a reporting system, a data warehouse and so on. Without going in further detail, I think it’s valid to say that non-production systems are typically running much lower average workloads than production. Exceptions exist and most of these systems are much more “spikey” in nature. Consider a development system that is sitting mostly idle the larger part of the time, but it peaks for a few hours to 100% when developers are trying some new functional modules. Or a data warehouse that is doing lots of write I/O first (DWH loads), then lots of reading and processing, then sits idle again for a long time. Needless to say that Enterprise Data Warehouse systems are often sized to meet end-of-month/year processing service levels, which only happens, surprise surprise, at the end of the month or year.
Some customers have told me they achieve good utilization without VMware but using other virtualization techniques. My take on that? At EMC, we think VMware is the best virtualization platform today for virtualizing databases, but if you can achieve similar optimizations with other platforms (i.e. IBM, SUN, or other Intel X64 hypervisors), then that’s just fine.
I’m just a bit skeptical on the actual results but prove me wrong, show me the numbers 🙂
![]()
Bart, I’m so with you on this! I spoke to a global investment bank recently who struggled with less than 5% average utilisation across their entire database platform of thousands of servers.
Think about the license money that is wasted on underutilised servers… It makes me dizzy! Anyone who isn’t trying to find a way to virtualize their database systems is just pooring money down the drain.
Yep, I see it happening all the time as well. That’s why I put a heavy focus on virtualization because it’s the only reasonable way to get a shot at better ROI.
But we need to continue hammering on the messaging because strangely enough, many customers don’t realise the full cost savings potential here.
Thanks for commenting!
BTW, awesome post on competitive blogging! Same experiences here 🙂
Reblogged this on VieVa!.
Enjoyed the article. Three points:
a) to lower database license costs, there is an even better technique than virtualization alone. it’s called postgreSQL, and it is not 10 times, not 100 times but infinitely cheaper than commercially licensed databases.
b) when virtualization is applied, be honest, and clearly explain that the performance may be a bit or a lot worse, but perhaps more importantly, it will not be reliable. the (exact) same batch will not take the same time to complete anymore, and 10% slower than last week is no reason to raise an incident on the batch performance – it’s not an incident but a consequence of the architecture. for some applications, this may be a viable argument to not virtualize. some things simply cost money to do right, and that’s not only the case in IT.
c) we discovered that some of our vmware-virtualized servers were not responding to network calls in a timely manner when they were being snapshotted or moved to a different host – causing lots of stability problems (which cost a lot of money). we checked, but this was actually not mentioned by vmware sales when we bought it 🙂
Jan-Marten,
a) Couldn’t agree more! Should have mentioned that in my post. Just that some applications are only supported on Oracle so you’d have to replace the application too. Certainly possible but not for the faint of heart. For some companies it would be too expensive, risky and complicated. And some customers just don’t want to go to other DBMS platforms and like to stick with Oracle. As my job is to focus on Oracle, my posts tend to be a bit biased towards it maybe 🙂
b) Not sure about unpredictable performance. Sounds like a real showstopper if you don’t get that under control. Will check with our EMC IT DBA to see whether he can confirm or deny that.
c) As in b. Let me check with our experts and I will get back on that.
Thanks for commenting!
Bart,
a) ” Just that some applications are only supported on Oracle so you’d have to replace the application too. ”
certainly – and that costs a lot of money. but one might certainly consider PostgreSQL for newly developed applications.
as to point b – utilization is not always the critical parameter, sometimes its the service time. for some applications the benefit of never having to wait (the predictable service time) outweighs the cost of the underutilized server. like a batch that must complete within T time in order to avoid business costs that outweigh the costs of an underutilized server by several orders of magnitude.
banks, hospitals, police, defense systems, DNS services etc.
thanks!