
 In my last post on ZFS I shared results of a lab test where ZFS was configured on Solaris x86 and using XtremIO storage. A strange combination maybe but this is what a specific customer asked for.
In my last post on ZFS I shared results of a lab test where ZFS was configured on Solaris x86 and using XtremIO storage. A strange combination maybe but this is what a specific customer asked for.
Another customer requested a similar test with ZFS versus ASM but on Solaris/SPARC and on EMC VNX. Also very interesting as on VNX we’re using spinning disk (not all-flash) so the effects of fragmentation over time should be much more visible.
So with support of the local administrators, I performed a similar test as the one before: start on ASM and get baseline random and sequential performance numbers, then move the tablespace (copy) to ZFS so you start off with as little fragmentation as possible. Then run random read/write followed by sequential read, multiple times and see how the I/O behaves.
Preparing the test
One thing that is important, is to reduce the effect of caching from storage array or other layers in the stack. The VNX we used has flash cache and FAST-VP tiering between different storage pools, but for tests like this, such optimization features cause too much variation in test results. So we had those disabled for the volumes used in our testing.
The database table was sized to be a large multiple of DRAM cache as well (my recommendation is that a data testset should be at least 10x the size of the largest cache in the stack – to minimize cache hit variations and see how the real spinning storage behaves). We decided upon 300GB for SLOB data. 300GB is roughly 37.5 million rows as each SLOB row is allocating exactly one 8K block.
Sequential reads
Fragmentation theoretically would be no issue at all if you do random reads anyway. But SLOB (our performance test tool) is designed to do random reads, writes or both, but never sequential. Like I wrote in previous posts, I wrote a small PL/SQL program to just do that – full table scans on SLOB data. The magic of SLOB is that each row is exactly one database block – so the number of rows scanned exactly matches the amount of data. So bandwidth = (number of rows scanned * 8KB) / (scan time in seconds). Plus, full table scans generate 100% sequential read – and, in many cases, multi-block I/O (depending on multi block read count in init.ora settings and the optimizer). With sequential reads we get an idea of the effect of fragmentation as I proved that sequential block sequences within data files get chopped in pieces because of ZFS “Copy on Write“. So ZFS would convert few but large sequential reads in many but small random reads – causing excessive seeks on disks with high latency and low bandwidth as a result. Of course you can mask this by throwing large amounts of DRAM or Flash cache into the mix (and this is exactly what Oracle does in their SUN/Oracle ZFS appliances). As long as your cache is warmed up – AND your active data set is not much larger than your total amount of cache – you don’t notice the fragmentation effects.
I’m just wondering why you would not buy an All Flash Array instead if your strategy is to match the flash size to fully hold your active data set!?
And it seems like Oracle agrees (causing some confusion): Oracle crashes all-flash bash: Behold, our hybrid FS1 arrays (But not really… It’s still a hybrid array with classic RAID – much like our VNX – but more on the FS1 later on this blog)
ZFS and ASM configuration
One of the questions to my previous post was why we had set the ZFS cache size so low (ZFS is known to work well with lots of RAM). So here the ZFS cache (arc) size on the host was set to 10GB. With 10GB we have a relatively large chunk of memory reserved for ZFS (and as ASM doesn’t do any caching at all, this is largely in favour of ZFS). But it’s still much less than 10% of the data size (closer to 4%) so we don’t avoid hitting the disk back-end this way. Another remark was on the pretty old Solaris/86 version we were using in the previous test – and if ZFS would have improved on more recent OS updates since then with better performance algorithms. This test was on SPARC with up-to-date Solaris, and with a server configuration that the customer also uses for production environment (they were running ZFS for many Oracle production databases).
Another thing in favor of ZFS is that we kept redo logs on ASM (even during ZFS tests) – you might argue that not much redo I/O will go on in full table scans, but having redo in the same ZFS pool as the SLOB data would cause much more fragmentation during write I/O. But in normal environments you would usually not have ASM and ZFS configured for the same database.
Calculations
To see the effects of fragmentation you should write at least a certain amount of random blocks to the database – if you randomly update all blocks in the tablespace you should have almost maximum fragmentation. In SLOB you can set the runtime or the total number of iterations – I picked runtime to make the test duration more predictable. 300GB is roughly 37.5 million rows, so I assumed a write ratio of 5000 iops which means it would take 37,500,000 rows / 5000 writes/s = 7500 seconds (about 2 hours) of random writes to fully fragment the tablespace. I decided to run 8 cycles of 15 minutes each so we can plot the results in a simple graph.
Initially our test volumes were configured on VNX SATA disks in RAID-6. SATA does not offer high numbers of random IOPS but my initial way of thinking was, if you compare ASM on slow SATA to ZFS on slow SATA, your numbers may not be very impressive but at least comparable. So we proceeded, only to find that the throughput on SATA was very low. The sequential read rate dropped to 5MB/s per disk and that’s lousy – even for SATA. I asked for SAS disks which resulted in much better performance. Of course the ZFS disks were also moved to SAS to keep comparing apples to apples. Still the write IOPS ratio was lower than my anticipated 5000 write IOPS but we decided to proceed and see what would happen. Basically this would mean that by the end of our test runs, we probably had not achieved maximum fragmentation yet – as we did not run the random write tests long enough to hit all database blocks. In the field things just aren’t always as perfect as in an isolated state-of-the-art lab environment.
Results
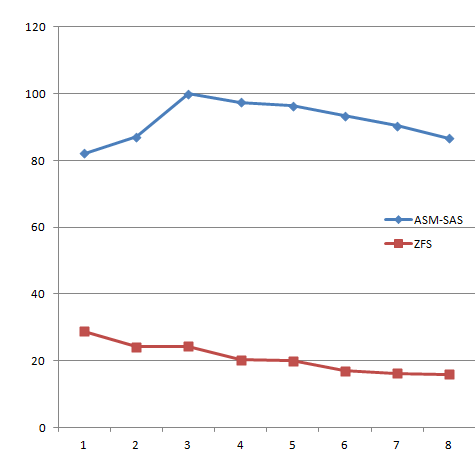
As the test was performed at a customer site, I will show only relative results where all bandwidth numbers are indexed against the maximum we achieved during the test (set to 100). Also I’m only looking at full table scan rates as random IOPS are not the key metric here.
ASM results
Interestingly enough, out of 8 runs, the 3rd run resulted in the best bandwidth, being 20% better than the first run, and there were no crazy jumps in the graph so the results are pretty repeatable (with a certain margin). After the 3rd run the bandwidth dropped a bit with each subsequent run. Possible cause? Not entirely sure, but my guess is this is because we’re on a VNX that is running some other workloads as well – not heavy stuff but still it can influence the results a bit. The percentage difference between the highest and lowest scan rate was roughly 20%.
ZFS results
We already noticed during the first test, directly after moving datafiles to ZFS, that the scan rate was significantly lower than the ASM results. Comparing the first runs of both tests, the difference was roughly 3X and getting worse and worse comparing the next runs until comparing run 8 of both and finding a 5.5X difference.
Just looking at ZFS, the first (highest) compared to the last (lowest) scan rate showed 1.8x difference and the trend was still downward.
Conclusion
Well, I’m going to let the results speak for themselves here. Due to time constraints I couldn’t run the tests longer to see if performance would drop even more. The slow but steady degradation of scan rate was exactly as I expected. The thing I did not expect was the huge difference even on the first run although I expected ASM to be a bit faster based on the testing I did previously on XtremIO.
It looks like Oracle themselves are aware of the limitations. If you look at the TPC-C benchmark on SPARC T5-8 and you digest the detailed results, you will see that Oracle did not use ZFS at all in this benchmark…
![]()